
刷新复杂Agent推理记录!阿里通义开源网络智能体超越DeepSeek R1,Grok-3
刷新复杂Agent推理记录!阿里通义开源网络智能体超越DeepSeek R1,Grok-3在互联网信息检索任务中,即使是很强的LLM,有时也会陷入“信息迷雾”之中:当问题简单、路径明确时,模型往往能利用记忆或一两次搜索就找到答案;但面对高度不确定、线索模糊的问题,模型就很难做对。
来自主题: AI技术研报
7360 点击 2025-07-08 11:05
在互联网信息检索任务中,即使是很强的LLM,有时也会陷入“信息迷雾”之中:当问题简单、路径明确时,模型往往能利用记忆或一两次搜索就找到答案;但面对高度不确定、线索模糊的问题,模型就很难做对。

Jack Clark 是最关注和熟悉中国在芯片、计算和模型上进展的 AI Lab 领导人之一。他毫不吝啬对中国 AI 进展的认可,将 DeepSeek R1 视作“推理模型大范围扩散”的起点,近期又把 HyperHetero 使用的异构集群叫做通过“超级智能进行持续自我训练”的垫脚石。

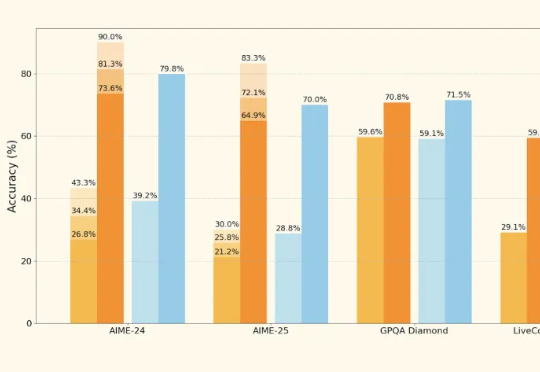
没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
“欧洲的OpenAI”Mistral AI终于发布了首款推理模型——Magistral。 然而再一次遭到网友质疑:怎么又不跟最新版Qwen和DeepSeek R1 0528对比?

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?

当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
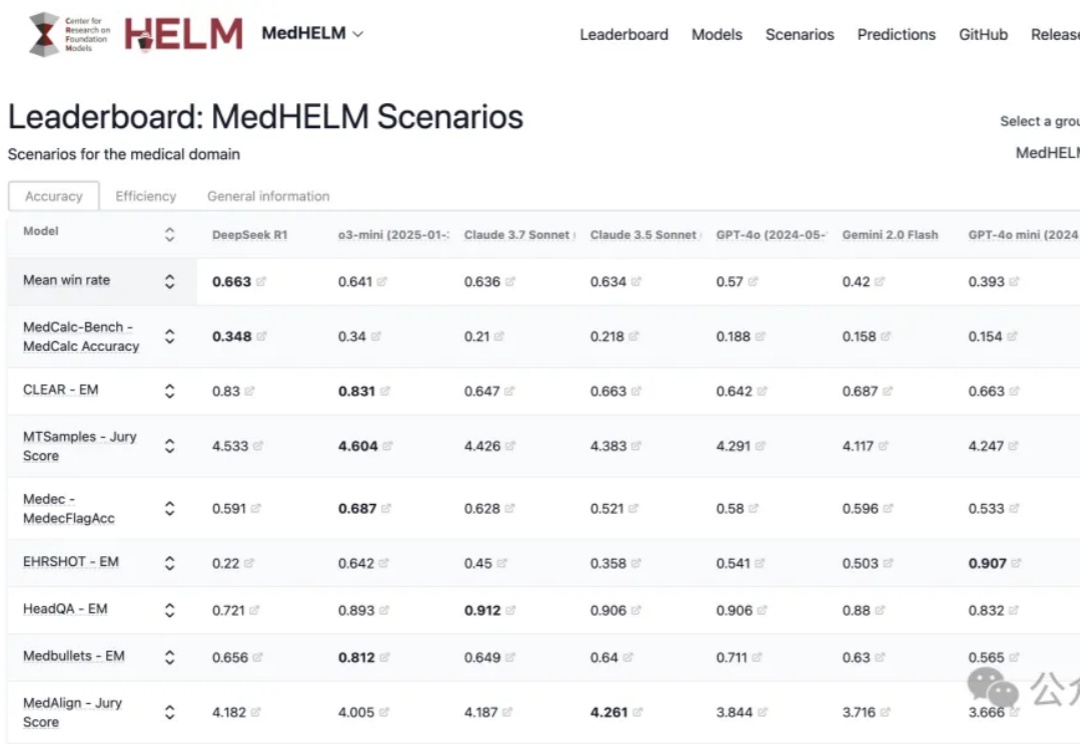
斯坦福最新大模型医疗任务全面评测,DeepSeek R1以66%胜率拿下第一!

MiniMax即将发布代号M+的文本推理模型,其表现将影响公司未来竞争力。面对DeepSeek R1的冲击,MiniMax采取国内C端不接入、海外接入的策略,并推出类Manus产品MiniMax Agent。公司通过品牌拆分(海螺AI更名)、纯API商业模式拓展市场,语音模型商业化效果显著,但未进入“基模五强”名单。新推理模型或成其保持行业地位的关键。
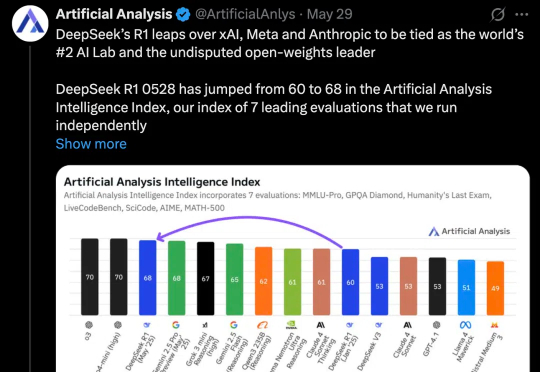
几天前,没有预热,没有发布会,DeepSeek 低调上传了 DeepSeek R1(0528)的更新。
DeepSeek 猝不及防地更新了,不是 R2,而是 R1 v2。